Table of Contents
A Data Analytics deciphers information and transforms it into data that can offer approaches to improve a business, in this way influencing business choices.
It accumulates data from different sources and deciphers examples and patterns – as such a Data Analyst set of working responsibilities should feature the explanatory idea of the job.

Key Reasons to Become a Data Analytics
- Profoundly popular field
- Generously compensated and Diverse Roles
- Advancing working environment situations
- Improving item guidelines
- Helping the world
Data Science Course with analytics calling is the most requested in 2020. It will increment furthermore and most top organizations are recruiting like Amazon, Facebook, Google, Intel, and Apple, and so forth and also one of the quickest developing areas and furthermore high paid occupations contributions.
This explains dreary errands what human sets aside on more effort to take on basic reasoning and critical thinking aptitudes. The use of AI has empowered organizations to tweak their contributions and upgrade client encounters. Prescient examination and AI have upset the medicinal services industry. It is sparing lives by empowering early discovery of tumors, organ inconsistencies, and then some.
Necessities: as an Information Examiner or Business Information Investigator
- Technical skill with respect to information models, database plan improvement, information mining, and division strategies
- Strong information and involvement in revealing bundles (Business Objects and so on), databases (SQL and so forth), programming (XML, JavaScript, or ETL structures)
- Knowledge of insights and experience utilizing factual bundles for examining datasets (Excel, SPSS, SAS and so forth)
- Strong expository aptitudes with the capacity to gather, arrange, investigate, and disperse huge measures of data with meticulousness and precision
- Adept at questions, report composing and introducing discoveries
- BS in Information Management or Statistics, Mathematics, Economics, Computer Science, etc.,
Looking forward to becoming a Data Scientist? Check out the Data Science Bootcamp Program and get certified today.
Data Analytics Salary in India
- New data expert (1 to 4 years) of experience: 4lakhs/annum
- Mid carrier expert (5 to 9 years) of experience: 6 to 7lakhs/annum
- Senior or developed bearer (5 to 9 years) of experience: >10lakhs/annum
The best 25 Data analytics Interview Questions and Answers.

1. What are some basic Data analytics obligations?

We enrolled a few specialists to assist you with getting a sneak look at the day by day obligations of a run of the mill data analytics.
- 1. Delivering reports
- 2. Spotting designs
- 3. Teaming up with others
- 4. Gathering information and setting up a framework
2. What is information cleaning?
Information cleaning likewise alluded as information purging, manages to distinguish and expelling blunders and irregularities from information so as to upgrade the nature of the information.
3. Notice what are the different strides in an investigation venture?
Different strides in an examination venture incorporate
- Problem definition
- Data investigation
- Data planning
- Modeling
- Validation of information
- Implementation and following
4. The distinction between Data Analytics versus Data Scientist?
In view of all that, you may be pondering about another conspicuous information job—the information researcher. While it’s sheltered to expect there is some cover in the sort of work they do, there are huge contrasts between information experts and information researchers.
Since the job of an information researcher is generally new and some of the time muddled, those in the field have attempted to characterize and separate it from that of the information examiner. We should separate it dependent on abilities and employment obligations.
Data analysts:
- Data analyst have moderate math, factual and coding abilities
- Have a solid business sharpness
- Develop key execution pointers
- Create representations of the information
- Utilize business insight and investigation apparatuses
Data Scientist:
- Data scientists have solid math and factual abilities.
- Have solid coding abilities and business ideas
- Identify patterns with AI
- Make forecasts dependent on information patterns
- Write code to aid information examination
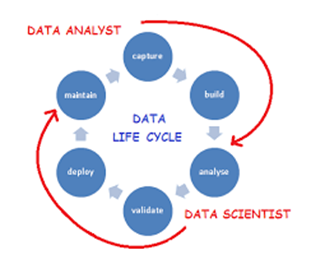
Despite the fact that information experts and information researchers have various foundations and qualities, remember that these jobs can be somewhat soft by the way they’re characterized. This implies duties may change contingent upon the association.
Sorts of information investigation
At its center, information examination is tied in with addressing questions and deciding. What’s more, similarly as there are various sorts of inquiries, there are likewise various kinds of information investigation relying upon what you’re planning to achieve. While there’s no unchangeable glossary of these kinds of information investigation, the people at Science Soft work superbly separating this work into four essential territories:
- Descriptive investigation answers, “What occurred?”
- Data Analytic investigation answers, “For what reason proficient something happens?”
- Predictive examination answers, “What is probably going to occur?”
- Prescriptive investigation answers, “What move ought to be made?”
Information examiners can tailor their work and answer to fit the situation. For example, if a maker is tormented with delays and impromptu stoppages, a demonstrative examination approach could help recognize what precisely is causing these deferrals. From that point, different types of examination can be utilized for fixing these issues.
5. Notice what is the obligation of a Data examiner?
The obligation of a Data investigator incorporate,
- Provide backing to all information examination and arrange with clients and staffs
- Resolve business-related issues for customers and performing review on information
- Analyse results and decipher information utilizing factual strategies and give continuous reports
- Prioritize business needs and work intimately with the board and data needs
- Identify new procedure or regions for development openings
- Analyse, distinguish and decipher patterns or examples in complex informational collections
- Acquire information from essential or auxiliary information sources and look after databases/information frameworks
- Filter and “clean” information, and audit PC reports
- Determine execution markers to find and right code issues
- Securing database by creating an access framework by deciding client level of access
6. What is required to turn into an information examiner?
To turn into an information investigator,
- Robust information on announcing bundles (Business Objects), programming language (XML, JavaScript, or ETL systems), databases (SQL, SQLite, and so forth.)
- Strong aptitudes with the capacity to investigate, sort out, gather and scatter enormous information with exactness
- Technical information in database plan, information models, information mining and division procedures
- Strong information on measurable bundles for investigating huge datasets (SAS, Excel, SPSS, and so forth).
7. Rundown of some best instruments that can be valuable for data analytics?
The following valuable tools for data analytics
- Rapid Miner
- Open Refine
- KNIME
- Google Search Operators
- Solver
- Node XL
- Wolfram Alpha’s
- Google Fusion tables
- Splunk
- R Programming
- Python
- Tableau
8. For what reason would you like to be Data investigator?
Generally, this kind of inquiry can fill in as an icebreaker. Notwithstanding, now and then, regardless of whether the questioners don’t unequivocally say it, they anticipate that you should answer an increasingly explicit
With these self-reflective questions, there’s not really a right answer I can offer you. There are wrong answers, though—red flags for which the employer is searching.
A few things you probably want to get across include:
- You love data.
- You’ve researched the company and understand why your role as a data analyst will help it succeed.
- You more or less understand what’s expected of your role.
- You’re confident in your decision.
9. Where do you see yourself in a decade?
This question can be a bit tricky. There are land mines all over the place. For example, you might be tempted to say you see yourself running the whole joint, but that’s obviously unwise. It demonstrates ambition and enthusiasm, but you’re all but saying you’re going to mutiny the leaders currently in charge.
You also don’t need to be tempted into personalizing this question too much. It can get your off-topic very easily. They’re not interested in whether you want to get married in ten years but rather in your career, and more explicitly your career with the company.
And, of course, avoid suggesting that the company you’re applying to is just a pit stop or a stepping stone. In other words, don’t come off as indecisive or unreliable.
Unlike with most questions, you’re going to want to keep the answer here pretty general, albeit as truthful and candid as you can without foregoing tact.
Sample answer: Within ten years, I hope to have grown with the company and to have advanced professionally toward my ultimate goal of becoming an impactful data analyst, and, eventually, data scientist. And, of course, I’d like to have a comfortable work-life balance and pay down my debts from college.
10. Describe a time when you had to persuade others. How did you get buy-in?
The trick to this question is to demonstrate that you not only persuaded others of a decision but that it was the right decision.
Sample answer As a data analyst intern at my last company, we didn’t really have a modern means of transferring files between co-workers. We used flash drives. It took some work, but eventually, I convinced my manager to let me research file-sharing services that would work best for our team. We tried drop box and Google Drive, but ultimately we settled on using Share point drives because it integrated well with some of the software we were already using on a daily basis, especially Excel. It certainly improved efficiency and minimized the wasted time searching for who had what records at what times.
11. How do you feel about data?
This question is a measure of your enthusiasm and passion for the field; it serves as a pretty good ice breaker or an end passant between questions. Really about the only thing, you don’t want to say is that you don’t have any sort of feeling for data.
Sample answer: I feel that data is king. If you just think about it at a sensory level, data propels everything we do. We take sensory input such as sight, taste, sound, smell, or touch, and we convert that data into actionable insights: only we do it so fast we don’t even realize. But that’s exactly what we do. I’m just the weird type of person who stops to think about the sources of that data and wants to learn what more I can glean from data and how I can use it both more efficiently and effectively.
12. Can you add 1-100 together right now?
This question is straightforward enough. You could, theoretically, compute the solution simply by adding the numbers in sequence, like so: 1+2+3… But this is impractical and probably not what the interviewer is looking for. Fortunately, there’s a formula called a series sum. It’s the number multiplied by itself plus 1, and the resulting solution divided by 2.
Sample answer: Thankfully, there’s a formula that can help with this:
100(100 + 1) = 10,100; 10,100 / 2 = 5,050.
13) List out roughly common issues faced by data analysts?
General mistakes faced by the data analyst
- Common misspelling
- Duplicate entries
- Missing values
- Illegal values
- Varying value representations
- Identifying overlapping data
14. What is the difference between data mining and data profiling?
Data mining is a process in which you classify patterns, irregularities, and correlations in large data sets to forecast outcomes. On the other hand, data profiling lets analysts observed and erase data.
Sample answer: Whereas data mining is concerned with gathering information from data, data profiling is concerned mainly with estimating the quality of data.
15. How have you dealt with messy data in the past?
Up to 80% of a data analyst’s time can be spent on cleaning data. Even more important when you consider that, if your data is unclean and produces inaccurate insights, it could lead to costly company actions based on false information. Yikes. That could mean trouble for you.
You want to validate not only that you know the difference between messy data and clean data but also that you used that information to cleanse the data.
Sample answer:
A client of ours was unhappy with our staffing reports, so I needed to pore over one to see what was causing their chagrin. I was looking at some data in a spreadsheet that contained information about when our call canter employees went to break, took lunch, etc., and I noticed that the time stamps were inconsistent: some had a.m., some had p.m., some didn’t have any specifications for morning or night, and worst of all, many of these employees were located in different time zones, so this needed to be made more consistent as well.
To solve the a.m. or p.m. dilemma, I made sure all times were specified in the military. This had two benefits: first, it eliminated the strings in the data and made the whole column numeric; second, it removed any need to specify morning or night as military time does this inherently. Next, I converted all times to UTC, this way all of the data was in the same time zone. This was important for the report I was working on because otherwise the data would be presented out of order and it could cause confusion for our client. Reorganizing the report’s data this way helped improve our relationship with the client, who, due to the time discrepancies, previously believed we were understaffed at specific times of day.
16. How many X is in Y place?
This question takes many forms, but the premise of it is quite simple. It’s asking you to work through a mathematical problem, usually figuring out the number of an item in a certain place, or figuring out how much of something could potentially be sold somewhere.
- Find how many malls are in a particular city in the country?
- Find how many engineering colleges with adequate facilities are available in state/district?
Some real examples from Glass door are mentioned above.
The idea here is to put you in a situation where you can’t possibly know something off the top of your head but to see you work through it anyway. That’s the trap, though. You don’t want to just give up and say, well, gee, I don’t know. As James Patounas, senior data analyst and associate director at Source One puts it, “I have been asked somewhat related as well as asked something similar. I personally would not admit ‘you can’t really know’ as an answer; or, at least, I would not hire someone that thought this was a sufficient answer.”
Mathematical modeling is normally an approximation of the actual world. It’s rarely a precise representation.
Basically, you wish to pull the info you do have, or at the least can approximate, and work yourself via a solution. Let’s take the number of windows in New York City for instance for the sample answer below.
Note: Statistics in this response do not necessarily convincingly reflect truths; they are estimates (there are actually 8.6 million people in NYC, rendering to 2017 data, for example).
Sample answer:
I believe there are about 10 million people in New York, give or take a couple million. Assuming each of them lives in a residential building, with three rooms or more, if there were one window per room that would make approximately 30 million windows. I’m making a few different assumptions that are probably inaccurate. For instance, that everyone lives alone and that the average size of their residences is just three rooms with one window per room. Obviously, there will be a lot of variations in reality. But I consider, in terms of residences, 30 million windows could be close.
Then you’d have to take windows for businesses, subway rail cars, and personal vehicles. If the average subway car seats 1,000 people, with 1 window per 2 seats, that’s 500 windows per car. A little more math: I’d guess there are at least enough subway cars to support the whole population of New York: so 10 million divided by 1,000 comes out to 10,000. So there are another 5 million windows for subway cars. If half of all people own their own vehicle, that’s another six windows per person, so 30 million more windows. I’d guess there are at least 100,000 businesses with windows in NYC. Let’s just say for the sake of argument there’s an average of 10 windows each. That’s another million. I’m sure there’s way more than that.
Overall, we’re at 66 million windows (30,000,000 x 2 + 5,000,000 + 1,000,000). All of this pretty much hinges on how close I am to the actual population of New York City. Also, there are other places to find windows, such as busses or boats. But that’s a start.
17. You have 10 boxes of cigarettes with 10 cigarettes in each box. All but one box has a cigarette which weighs 10g each. The exception’s cigarette weighs 11g each. How would you determine which box has 11g cigarette using a scale only once?

This question would be really difficult to figure out on the spot. Fortunately, it’s a puzzle with answers all over the place online.
The identifying factor for each of these boxes of cigarettes is weight; fortunately, we have only one different box. Unfortunately, we only have one chance to weigh, so we couldn’t just weigh each box individually.
Instead, we can solve the problem if we put a different number of cigarettes from each box into a new box to weigh it and reverse engineer the identity of the heavier box.

Let’s take 1 cigarette from the first box, 2 from the second box, 3 from the third box, and so on. This way each box we’ve drawn from is uniquely identifiable by the number of cigarettes missing. I have used my middle school-level illustration skills to draw this procedure.
The total number of cigarettes in the box can be calculated now using the series sum formula alluded to in question
5: n(n+1)/2. If we plug the numbers in, we should get 55. Now we have to multiply it by the weight of each cigarette, which is 10g. That means the total weight of the cigarette should be 550g, in a perfect world.
But we’re not in a perfect world. One of these boxes is different. Let’s say, for argument’s sake, the third box is the one that has the heavier 11g cigarette. The weights would look like this: 10, 20, 33, 40, 50, 60, 70, 80, 90, and 100. If you weighed this, in total, it would add up to 553. Clearly, one of these boxes has botched things up.
To find out which one, we can subtract 550 from 553, getting 3. In other words, the third box is the odd one out. The formula, then, would look like this: W – w(n(n+1)/2), where W = total weight and w = weight of each cigarette (except the odd ones).
Note that we’ve labeled the box 1-10 based on the number of cigarettes taken from it. The difference won’t necessarily be this number, however. If the box were more than 1g heavier or lighter, we’d have to do more math. Say, for example, the odd cigarette weighed 12g instead; the difference would have been 6. This still points to the third box because we know that the odd cigarette is 2g heavier than the other cigarette. If we divide 6/2 will get 3
Sample answer: You can find the heavier box of cigarettes by taking a different number of cigarettes, up to 10, from each box, placing them in a new box, and weighing the result.
For example, you take 1 from the first box, 2 from the second, all the way up to the final box, from which you’ll take all 10 cigarettes and place the final box, from which you’ll take all 10 cigarettes and place them in the new box. If you use a series sum to find the number of cigarettes (or you’ve counted them as you placed them in the box), and multiply the total number by the majority weight (10 in this instance), you can then use this number to find out where the weight “problem” is. Weigh the cigarettes you’ve placed into the new box and subtract this number from the projected weight. The difference will be the box from which you took that many cigarettes. This is the heavier box.
18. What would be your top interview question for prospective data analysts? How would you answer this question?
Suppose that you were provided a flat-file ( Excel, CSV, etc. & #41; to manipulate and load into a database. It contains millions of rows. Suppose that you were provided a flat-file ( Excel, CSV, etc. & #41; to manipulate and load into a database. It contains millions of rows.
While loading the database from data, you have to perform an analysis, in case building some type of mathematical model. While you can’t ever be 100% confident that everything was processed and loaded correctly, you can do some things in order to ensure that you are reasonably confident. Describe for me what you would do.
Worldwide valuation: Perform comparative examination of the raw file and the loaded data by the following:
- Count the number of rows
- Count the number of columns
- Sum the numeric columns
- Check the data types (i.e., if I thought that a column was entirely filled with dates then that should persist)
Localized assessment
- Randomly pick a few rows and manually compare
- Check the distinct elements in textual fields (i.e., if categories A, B, and C exist before, then that’s all I should see after)
- Check conversions if applicable (i.e., if NA is used for non-responses for numerical values then the database won’t accept it if we’re storing the data in a numerical field)
19. Describe the process of data analysis?
The process of data analysis includes data collection, data inspection, data transformation, and modeling data for valuable insights and support the organization with better decision making solutions. The steps which include in the process of data analysis are mentioned below:
Data Exploration
It defines exploring the data for analysis. When a data analyst has identified the business problem, it is suggested to go through the data provided by the client and then analyze the root cause of the problem.
Data Preparation
Data is collected from the client or any other sources are usually in the raw form. It plays an important role in the process of data analysis as it detects the missing values and outliers or any other data anomalies and treats accordingly to model the data.
Data Modelling
Once the data is prepared, the process of data modeling starts where the model is run repeatedly for improvements. It ensures that the best possible result is provided.
Validation
In the process of validation, the model developed by data analysts and the model provided by the client is validated against each other to find out if the developed model will meet the business requirements.
Deployment of the Model and Tracking
This is the final step where the model is deployed and is tested for efficiency and accuracy.
20. What are the major differences between data mining and data analysis?
| Data Mining | Data Analysis |
| Data mining usually does not require any hypothesis. | Data analysis starts with an assumption or a question |
| Data mining is dependent on well-documented data and cleaning of data. | Data analysis involves data cleaning. |
| Data mining outcomes are not always easy to interpret. | The outcome after data analysis is interpreted by the Data analysts conveyed to the stakeholders |
| Data mining algorithms automatically develop equations. | Based on the hypothesis, data analysts will have to develop their own equations. |
21. What are the important steps in the data validation process?
Data Validation is basically the process of validating data. This step plays one of the important roles in the process of data analysis. It mainly involves two processes namely, Data Screening and Data Verification.
Data Screening
Various algorithms are used in this step in order to screen the entire data and find out all inaccurate values.
Data Verification
This step is mainly to evaluate each and every suspected value in various use-cases and then decide whether to include those values in the data or not or suppose the values have to be rejected as invalid or if they have to be replaced with some redundant values.
22. What are the different types of Hypothesis Testing in Data analytics?
The different types of hypothesis testing are as follows:

- T-test: It is used for the typical deviation is unidentified and the sample size is moderately small.
- Chi-Square Test for Independence: These tests are used to discover the significance of the association between categorical variables in the people sample.
- Homogeneity of Variance (HOV): tests the similarity of dispersion parameters in several population samples.
- Analysis of Variance (ANOVA): This kind of hypothesis testing is used to analyze differences between the means in a variety of groups. This test is frequently used similarly to a T-test but, is used for a lot more than two groups.
- Welch’s T-test: This test is used to discover the test for equality of means between two population samples
23. Mention the key skills required for Data analytics.
A data analyst must have the following skills
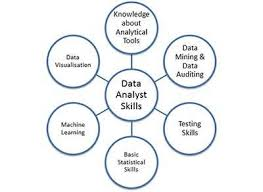
- Database knowledge
- Database management
- Data Blending
- Querying
- Data manipulation
- Predictive Analytics
- Basic descriptive statistics
- Predictive modeling
- Advanced analytics
- Big Data Knowledge
- Big data analytics
- Unstructured data analysis
- Machine learning
- Presentation skill
- Data visualization
- Insight presentation
- Report design
24. Describe univariate, bivariate, and multivariate analysis in Data analytics.
The three types of analysis methodologies have single, double, or multiple variables.
Uni-variate analysis
It’s only 1 variable and therefore you will find no relationships, causes. The key facet of the univariate analysis would be to summarize the information and discover the patterns within it to produce actionable decisions.
Bi-variate analysis
This deals with the partnership between two sets of data. These sets of paired data result from related sources or samples. A few of the tools used to analyze such data includes chi-squared tests and t-tests once the data have a correlation. The potency of the correlation between both data sets will soon be tested in bivariate analysis.
Multivariate analysis
This is similar to bivariate analysis. It is a couple of techniques useful for the analysis of data sets that contain more than one variable, and the techniques are especially valuable whenever using correlated variables.
25. What is the difference between linear and logistic regression?
Linear regression is a statistical model that attempts to fit the best possible straight line between the independent and the dependent variables when a set of input features are given. As the output is continuous, the cost function measures the distance from the observed to the predicted values. It can be said to be an appropriate choice to solve regression problems, for example, predicting sales numbers.
On another hand, Logistic regression gives probability as its output. By definition, it is a bounded variable between zero and one, because of the sigmoid activation function. It is appropriate to solve classification problems, for instance, predicting whether a transaction is a fraud or not.
26. What is the time series analysis in Data analytics?
Time series analysis is really a statistical technique that handles time-series data or trend analysis. It will also help to comprehend the underlying forces leading to a particular trend in the time series data points. It is the data that is in a series of particular time periods or intervals. The types of data considered are –
- Time series data – This is a set of observations on the values that a variable takes at different times
- Cross-sectional data – The data of one or more variables that are collected at the same point in time.
- Pooled data – This is the combination of both time-series data and cross-sectional data
- Time series analysis can be performed in two domains – frequency domain and time domain.
Recommended Read:
- Top 15 Best Data Science Course in Mumbai
- Top 10 Data Science Course in Pune
- Top 10 Data Science Course in Bangalore
- Top 10 Data Science Courses in Nagpur
- Top 20 Data science course in Delhi NCR
- Top 10 Data Science Course In India
Also check this video:
English Speaking Course by Henry Harvin®
Ranks Amongst Top #5 Upskilling Courses of all time in 2021 by India Today
View Course
E&ICT IIT Guwahati Best Data Science Program
Ranks Amongst Top #5 Upskilling Courses of all time in 2021 by India Today
View CourseRecommended Programs
Data Science Course
With Training
The Data Science Course from Henry Harvin equips students and Data Analysts with the most essential skills needed to apply data science in any number of real-world contexts. It blends theory, computation, and application in a most easy-to-understand and practical way.
Artificial Intelligence Certification
With Training
Become a skilled AI Expert | Master the most demanding tech-dexterity | Accelerate your career with trending certification course | Develop skills in AI & ML technologies.
Certified Industry 4.0 Specialist
Certification Course
Introduced by German Government | Industry 4.0 is the revolution in Industrial Manufacturing | Powered by Robotics, Artificial Intelligence, and CPS | Suitable for Aspirants from all backgrounds
RPA using UiPath With
Training & Certification
No. 2 Ranked RPA using UI Path Course in India | Trained 6,520+ Participants | Learn to implement RPA solutions in your organization | Master RPA key concepts for designing processes and performing complex image and text automation
Certified Machine Learning
Practitioner (CMLP)
No. 1 Ranked Machine Learning Practitioner Course in India | Trained 4,535+ Participants | Get Exposure to 10+ projects
Explore Popular CategoryRecommended videos for you
Learn Data Science Full Course
Python for Data Science Full Course
What Is Artificial Intelligence ?
Demo Video For Artificial intelligence
Introduction | Industry 4.0 Full Course
Introduction | Industry 4.0 Full Course
Demo Session for RPA using UiPath Course
Feasibility Assessment | Best RPA Using Ui Path Online Course